



 , , , 张治国1
, , , 张治国1
2. 南方医科大学南方医院 广东 广州 510515;
3. 华中科技大学同济医学院附属同济医院 湖北 武汉 430030
, , ,
ZHANG Zhi-guo1 2. Nanfang Hospital of Southern Medical University, Guangzhou Guangdong 510515, China;
3. Affiliated Tongji Hospital, Tongji Medical College of Huazhong University of Science and Technology, Wuhan Hubei 430030, China
自2009年新一轮医药卫生体制改革启动以来,基本医疗保险支付制度改革受到广泛关注。按人头付费作为支付制度改革的一个重要方面,各地纷纷开展有关试点。按人头付费是指医疗保险经办机构按协议规定的时间(一月、一季度或一年),根据定点医疗机构服务的参保人数和每个人的支付定额标准,向定点医疗机构支付费用,定点医疗机构按协议规定提供医疗服务的费用支付方式。[1-2]国际上,按人头付费实践中,通常采用风险调整机制,即根据不同人群的患病风险及费用高低,调整人头费用标准。风险调整机制已被西方国家广泛利用,而我国各地在实践中尚较少体现。[3]本文以深圳市社区门诊统筹为例,探索在大陆卫生政策背景下如何建立基于风险调整的按人头付费标准。
2014年1月1日,深圳市开始施行新的《社会医疗保险办法》,将基本医疗保险根据缴费及对应待遇分设为一档、二档、三档三种形式。二档和三档参保人员需要绑定一家社区健康服务中心作为其门诊就诊机构,每家社区健康服务中心需选定一家医院作为其结算医院。社保基金对社区健康服务中心支付费用时,先支付给社区健康服务中心所属的结算医院,再由结算医院进行分配。二档和三档实行社区门诊统筹,建立门诊统筹基金,并采取按人头付费。人头费用标准为缴费基数的0.2%(缴费基数为上一年度在岗职工月平均工资)。
| 表 1 2014—2015年深圳市社会医疗保险二档和三档社区门诊统筹人头费标准 |
本研究数据来源于深圳市社会保险基金管理局,数据时间段为2014年1月1日—2015年12月31日,样本社区健康服务中心为深圳市6个中心区人民医院下属的77个社区健康服务中心,共有3个数据库:
(1) 参保人员基本信息库:样本社区健康服务中心每月签约服务的二档和三档参保人员个人基本信息,原始数据库包含16 904 690条记录、6个变量(参保人员唯一识别编号、年龄、性别、档次、绑定社区健康服务中心编码、参保月份)。
(2) 社区健康服务中心门诊补偿数据库:样本社区健康服务中心二档和三档参保人员就诊补偿信息,原始数据库包含8 938 113条记录、11个变量(参保人员唯一识别编号、年龄、性别、就诊时间、就诊社区健康服务中心、档次、诊疗项目或药品编码、诊疗项目或药品名称、就诊费用、医保补偿费用、个人现金支付费用)。
(3) 参保人员门诊大病数据库:样本社区健康服务中心二档和三档参保人员中患有门诊大病的参保人员信息,原始数据库包含729条记录、2个变量(参保人员唯一识别编号、大病类型编码)。门诊大病为《深圳市社会医疗保险办法》中确定的7种门诊大病,即恶性肿瘤、颅内良性肿瘤、慢性肾功能衰竭、器官移植后门诊用抗排斥药、血友病、再生障碍性贫血、地中海贫血。
1.2 数据清理运用SPSS24.0对原始数据库进行数据清理,建立最终运用于分析和建模的数据库。
(1) 删除重复记录:运用SPSS软件的标识重复个案功能,删除社区健康服务中心门诊补偿数据库中的重复记录430 526条、参保人员门诊慢病或大病数据库中的重复记录37条。
(2) 数据库链接:运用SPSS的数据合并功能,根据参保人员唯一识别编号将参保人员基本信息库和社区健康服务中心门诊补偿数据库数据链接。
(3) 年龄数据异常的处理:通过描述性统计分析发现,2014年0岁参保人数异常增多,可推测为数据录入空缺,系统默认为0岁。因此,根据2015年年龄对2014年年龄进行校正:用个体2015年年龄减去2014年年龄,若差值等于0、1或2,则认为2014年年龄信息正确;若差值等于其它值,则认为2014年年龄信息错误,采用“2015年年龄减1”进行替换。
(4) 疾病相关变量的生成:对于个体费用预期而言,最有效最重要的变量是疾病诊断。国外学者开发了众多基于诊断的或基于药物的风险调整工具,用于进行人头费的风险调整。[4-5]由于深圳市门诊补偿数据库中并没有个体疾病诊断信息,而只有个体诊疗项目和使用药物情况。因此借鉴基于处方药物的风险调整工具的基本思想,通过药物来标识个体所患疾病情况。由药学专家根据治疗疾病所使用的特异性的药物,标识出4种慢性病,分别为支气管哮喘或慢性阻塞性肺气肿、糖尿病、高血压、活动性肝炎。在补偿数据库中,如果患者使用了某一药物,则将其标识为相应的慢性病患者。
1.3 研究方法本研究采用描述性统计对参保人员参保情况和就诊情况进行描述,采用两部模型进行风险调整模型建模估计,其中参保者参保期间内门诊就诊概率的估计采用Logistic回归,就诊者就诊费用的估计采用广义线性模型。在此基础上预测参保者月均就诊总费用及相应的医疗保险支出。使用两部模型能够解决数据具有大量零值的问题,而使用广义线性模型能够解决数据偏态分布的问题,也能够杜绝或缓解异方差问题。
Logistic回归纳入自变量为性别、年龄、档次、就诊社区健康服务中心,采用基于最大似然函数的向前逐步回归法筛选自变量(变量纳入的水平为0.05,变量剔除的水平为0.10)。广义线性模式纳入自变量为性别、年龄、档次、社区健康服务中心、有无慢病或大病,纳入因变量为月均就诊费用。根据以往的研究结果,在拟合广义线性模型时,一般采用Gamma分布作为分布函数,自然对数变换作为连接函数。[6]
2 结果 2.1 参保、就诊和费用情况运用参保人员基本信息库分析参保人群基本情况,77个社区健康服务中心两年共有参保者1 640 942人,其中2014年1 127 540人,2015年1 208 088人。2014年全年都参保者为321 599人,占该年全部参保人数的28.5%;大部分人群并没有连续参保,其中11.1%的人仅参保1个月。2015年情况类似。推测可能的原因是深圳市参保人群中外来劳务人员占较大比重,这些人群流动性大,容易中断参保。
运用社区健康服务中心门诊补偿数据库分析2014和2015年就诊人群信息。两年共1 502 335就诊人次,其中2014年为746 481人次,2015年为755 854人次。2014年及2015年人均就诊次数分别为3.72和3.73次,中位数同为3次。由于不同的参保者参保月数不同,以年人均就诊次数来反映就诊情况不尽合理,因此根据参保者中就诊人群的参保月份,计算该参保者月均就诊次数。2014年及2015年月人均就诊次数分别为0.42和0.41次,中位数分别为0.29和0.27次。
| 表 2 参保者中就诊人群的就诊次数情况 |
对就诊人群的次均就诊费用进行分析,2014和2015年参保者中就诊人群的次均就诊费用分别为87.46元和88.22元,实际补偿比分别为72.19%和71.45%(表 3)。
| 表 3 次均就诊费用、补偿费用和个人现金支付费用情况(元/人次) |
同计算月均就诊次数一样,由于部分参保人员未全年参保,因此使用参保月份对年度就诊总费用进行调整,计算月人均就诊费用,2014年为36.33元、2015年为36.09元(表 4)。
| 表 4 参保者中就诊人群的月人均就诊费用、补偿费用情况(元) |
Logistic回归的结果显示,年龄、性别、档次和所在社区健康服务中心均被纳入模型当中,没有变量被剔除。预测的参保者参保期间内门诊就诊概率最大值为0.862,最小值为0.012,均值为0.177。各变量参数的估计结果如表 5。
| 表 5 Logistic回归模型的参数估计 |
总体模型的似然比检验结果P<0.001,各变量回归系数的Wald卡方检验结果P<0.001(少数几个年龄、社区健康服务中心哑变量回归系数P>0.05,但年龄、社区健康服务中心变量总体回归系数P<0.001),总体模型及各变量均具有统计学意义。模型拟合度评价指标中,Cox & Snell决定系数为12.5%,Nagelkerke决定系数为20.6%,模型拟合效果较好。比较有无就诊的实际人数和预测人数可以看到,对没有就诊的人群预测准确率高达97.5%,而对于有就诊的人群,预测准确率较低,仅为17.3%,总体预测率为83.3%(表 6)。
| 表 6 Logistic回归模型的预测准确率分类 |
对总体模型进行似然比检验,P<0.001,可以认为模型总体具有统计学意义。对模型中各变量进行Wald卡方检验,其中性别、有无慢病或大病两个变量P<0.001,档次P<0.01,年龄和社区健康服务中心虚拟变量大部分P<0.001,可以认为各变量具有统计学意义。模型偏差与自由度比值为1.195,Pearson卡方值与自由度比值1.517(一般认为比值小于2时,模型拟合较好)。各变量参数的估计结果如表 7。
| 表 7 广义线性模型的参数估计结果 |
通过将Logistic回归模型得到的预测概率和广义线性模型得到的预测费用相乘,可以计算得出参保者参保期间内门诊的预测医疗费用支出,再除以相应的参保月份,即可得出预测的参保者月人均费用。全体参保者实际发生月均总费用为7 251 523.05元(未就诊个体费用视为0),月人均费用为6.4313元。结果显示,全体参保人群月均总费用预测值为6 956 423.48元,月人均费用为6.1696元。
通过对个体水平的实际费用和预测费用相加,得到社区健康服务中心水平的实际费用和预测费用。从社区健康服务中心水平的拟合情况来看,70个社区健康服务中心的预测值低于实际值,剩余6个社区健康服务中心的预测值高于实际值(2014年还有1个社区健康服务中心未成立)。可见,使用两部模型进行估计造成了普遍的低估。通过计算两者差距占实际值的比例,差距在实际值±1%以内的社区卫生服务中心有8个,±3%以内的有19个,±5%以内的有38个,±10%以内的有67个,另外9个社区健康服务中心预测偏差超过实际值的10%(表 8)。
| 表 8 两部模型社区健康服务中心水平拟合情况 |
风险调整的两部模型中,通过第一部参保者参保期间内门诊就诊概率模型分析得到影响个体门诊就诊概率的因素,包括性别、年龄、档次和所在社区健康服务中心;通过第二部就诊者就诊费用模型分析得到影响个体就诊费用的因素,包括性别、年龄、档次、所在社区健康服务中心和有无慢病或大病。在实际操作中,需要结合各选择标准,全面权衡预期能力、激励机制设计、可操作性及管理成本等进行风险调整因素的选择。综合考虑,可以将性别、年龄、档次和有无慢病或大病4个因素作为风险调整因素。对于新参保的没有患病信息的个体,可以将性别、年龄和档次作为风险调整因素。
本研究使用分组计算法(或者叫矩阵法)计算人头费标准。矩阵法是指依据各个调整因素(如年龄、性别)及其不同的水平(年龄可分为不同年龄组,性别分为男女),将全体人群划分为不同的组别,分别估计各组别的人头费率。[7-8]由于深圳市60岁及以上的男性参保人群和50岁及以上的女性参保人群多数参加一档,参加二档或三档的数量极少,这一部分人群分别将其归入男性59岁、女性49岁组。此外,16岁以下人群参加二档,不参加三档。通过将费用相近或者某些包含人数过少的组别进行合并,最终将全部参保人群划分为52个组别,并计算其预期费用(表 9)。
| 表 9 不同性别、年龄、档次和有无慢病或大病个体组别绝对费用与相对权重 |
各组别的预期费用,乘以一个固定的实际补偿比,就可以作为各组别的人头费。更为恰当的方法是计算各组别的相对权重:
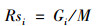
|
其中,Gi为组别i人群的预期费用,M为全体参保人群的平均预期月人均费用。相对权重又常称作风险得分(Risk Score,Rs)。如0岁男性二档参保人员,无慢病或大病,其预期月人均费用为17.01元,全体参保人群的平均预期月人均费用为6.17元,则可以算得该组别人群的相对权重为17.01/6.17=2.76,即该组别人群的预期月人均费用支出是全部参保人群的2.76倍。
将未经风险调整的人头费称作基准人头费(Base Per Capita Rate)。通过基准人头费和风险得分,可以计算出各组别的人头费:
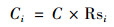
|
其中,C为基准人头费,Ci为组别i的人头费。当全体参保人群的平均预期月人均费用作为基准人头费时,各组别的预期月人均费用即为各组别的人头费。采用相对权重设定人头费标准,假定不同年度各组别的相对医疗费用没有变化,则相对权重不变,那么仅需根据不同年度基准人头费的变化即可得出各组别人头费标准。这一基准人头费可以是通过模型测算的全体参保人群月人均费用,也可以是由其它方式确定的标准,如前述深圳市实际采用的根据门诊统筹资金预算确定的人头费标准。
3 讨论 3.1 对风险调整模型的讨论两部模型较好地解决了非负值、大量零费用支出、偏态分布等问题,但是并不能够解决个体费用数据间可能存在的非独立问题。在参保和补偿数据集中,个体嵌套于社区健康服务中心中,而社区健康服务中心又嵌套于结算医院中,是一个多层结构的数据集。为解决个体非独立的问题,需要改进模型,使用混合效应模型,分别建立以Logistic回归为第一部、广义线性模型为第二部的两部模型。此外,本研究采用的数据集为样本社区健康服务中心的全部参保人员和就诊人员的数据,由于参保人员的流动性,如果参保人员在非样本社区健康服务中心有过就诊,那么该个体费用的预测值将低于实际值。
3.2 对风险调整因素的讨论门诊诊断信息的缺失严重影响了模型预测的准确度。作为初期的探索性研究,本文仅仅根据治疗疾病所使用的较为特异的药物,标识了4种慢性病。当然,此做法也存在一定的局限性:(1) 药物与疾病并不是完全一一对应的,虽然本文选取的药物都较为特异,但也可能存在超说明书用药等情况;(2) 由于尽量选取较为特异的药物,因此不可避免造成个体虽然患有糖尿病、高血压等疾病,但是使用了非特异的药物治疗,会将其标识为非慢病患者;(3) 本文仅选取了4种慢性病,数量上显得略少。对于2014年年龄信息错误的问题,本文根据2015年的年龄信息对其修正,以尽量减少数据错误带来研究上的偏误。
3.3 对人头费计算的讨论统计分析结果显示,2014年全体参保人群实际发生的月人均总费用为6.43元,预测费用值为6.17元。而深圳市人力资源与社会保障局设定的基准人头费2014年1—6月为9.84元,7—12月为10.44元。关于门诊统筹筹资总额及基准人头费的计算,世界银行在其报告中推荐了两种方法:自下而上法(Bottom-up costing)和自上而下法(Top-down allocation)。[9]自下而上法通过估计个体卫生服务支出来计算门诊统筹所需资金总量和基准人头费。自上而下法则根据预先确定的比例从医疗保险筹资总额中提取一部分作为门诊统筹资金,然后再根据参保人员总数计算分配到每一个参保个体头上的资金额度(即基准人头费)。事实上,本研究计算得到的预测值采用的方法为自下而上法,而深圳市人力资源与社会保障局设定的方法为自上而下法。可以看到,两种方法得到的数据相差很大,采用自下而上法更加符合实际卫生支出情况。
4 建议 4.1 推动基于风险调整的按人头付费的实施本研究发现,不同年龄、性别、档次和有无慢病或大病的人群,卫生服务支出不同。采用未经风险调整的按人头付费,容易使不同社区卫生服务中心面临不一样的财务风险,造成不公平的分配以及社区卫生服务中心进行风险选择等一系列负向激励。因此,有必要推动实施基于风险调整的按人头付费。本文以深圳市为案例,综合考虑数据可获得性、实施的可操作性和简便性等因素,探讨了如何进行风险调整并最终计算经过风险调整的人头费标准,为深圳市及其他城市进行具体的实践提供了有益参考。
4.2 完善医疗保险信息系统,确保数据收集质量人头费标准的计算依赖于数据的准确性。医疗保险信息系统越完善,数据收集的质量越高,费用标准的估计就越准确。深圳市应该逐步将门诊数据字典库中各变量的缺失数据(如门诊数据字典中显示门诊补偿数据库中含有诊断编码、就诊医疗机构编码、科室编码、科室名称、人员类别、门诊类别、特病类别、特检类别、参保类型、医疗机构内部药品或诊疗项目编码、社保统一药品或诊疗项目编码、医保结算项目代码、药品或诊疗项目名称、总金额、记账金额、现金等变量,然而实际获得的数据库中诊断编码、科室编码、科室名称、人员类别等变量数据基本为空缺值)收集完善,并提高年龄等信息的填报准确度。考虑到实际工作的难易程度和成本,可以先完善年龄、人员类别等人口经济学变量,而门诊诊断则待时机成熟时逐步进行完善。
| [1] | 中华人民共和国国家标准社会保险术语第4部分: 医疗保险[M]. 北京: 中国标准出版社, 2015. |
| [2] | National Center for Biotechnology Information. MeSH:Capitation Fee[EB/OL].(2015-07-24)[2017-03-15]. http://www.ncbi.nlm.nih.gov/mesh/68002204 |
| [3] | 吴荣海, 王立洋, 曹志辉, 等. 我国基本医疗保险门诊统筹按人头付费方案分析[J]. 中华医院管理杂志, 2015, 31(4): 266–270. |
| [4] | Winkelman R, Mehmud S. A Comparative Analysis of Claims-Based Tools for Health Risk Assessment[R]. The Society of Actuaries, 2007. |
| [5] | Sales A E, Liu C F, Sloan K L, et al. Predicting costs of care using a pharmacy-based measure risk adjustment in a veteran population[J]. Med Care, 2003, 41(6): 753–760. |
| [6] | Jones A M. Models for health care. In Hendry D, Clements M. Oxford handbook of economic forecasting[R]. Oxford University Press, 2011. |
| [7] | Buchner F, Wasem J. Needs for further improvement:risk adjustment in the German health insurance system[J]. Health Policy, 2003, 65(1): 21–35. DOI:10.1016/S0168-8510(02)00114-8 |
| [8] | New Zealand Ministry of Health. Population-based Funding Formula 2003[R]. Wellington: Ministry of Health, 2004. |
| [9] | Langenbrunner J C, Cashin C, O'Dougherty S. Designing and implementing health care provider payment systems:how-to manuals[M]. Washington DC: The World Bank, 2009. |
(编辑 薛 云)